Let’s say you want to get an email notification when the free disk space on your server drops below some threshold level. There are many ways to go about this, but here is one that does not require you to install anything new on the system and is easy to audit (it’s a 4-line shell script).
The df Utility
df is a command-line program that reports file system disk space usage, and is usually preinstalled on Unix-like systems. Let’s run it:
$ df -h /
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/ubuntu--vg-ubuntu--lv 75G 23G 51G 32% /The “-h” argument tells df to print sizes in human-readable units. The “/” argument tells df to only output stats about the root filesystem. The “Use%” field in the output indicates the root filesystem is 32% full. If we wanted to extract just the percentage, df has a handy “–output” argument:
$ df --output=pcent /
Use%
32%We can use tail to drop the first line, and tr to delete the space and percent-sign characters, leaving just the numeric value:
$ df --output=pcent / | tail -n 1 | tr -d '% '
32The Disk Space Monitoring Script
Here is a shell script that looks up the free disk space on the root filesystem, compares it to a defined threshold value (75 in this example), then does some action depending on the result:
pct=$(df --output=pcent / | tail -n 1 | tr -d '% ')
if [ $pct -gt 75 ];
then
// FIXME: the command to run when above the threshold
else
// FIXME: the command to run when below the threshold
fiWe can save this as a shell script, and run it from cron at regular intervals. Except the script does not yet handle the alerting part of course. Some things to consider:
- Sending emails directly from servers is a little fiddly: you need to install an MTA and configure it with working SMTP credentials.
- Rather than sending a notification after every check it would be much better to send a notification only when the available disk space crosses the threshold value.
Healthchecks.io
Healthchecks.io, a cron job monitoring service, can help with the alerting part:
- You can send monitoring signals to Healthchecks.io via HTTP requests using curl or wget.
- Healthchecks.io handles the email delivery (as well as Slack, Telegram, Pushover, and many other options).
- Healthchecks.io sends notifications only on state changes – when something breaks or recovers. It will not spam you with ongoing reminders unless you tell it to.
- It will also detect when your monitoring script goes AWOL. For example, when the whole system crashes or loses the network connection.
In your Healthchecks.io account, create a new Check, give it a descriptive name, set its Period to “10 minutes”, and copy its Ping URL.
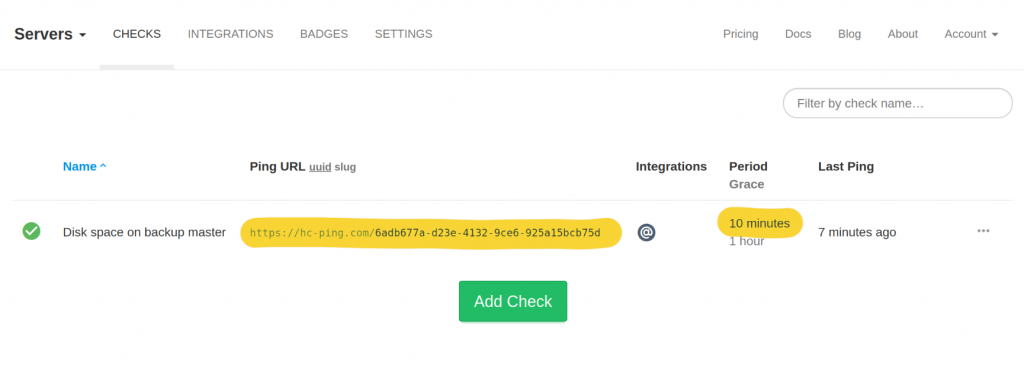
The monitoring API is super-simple. To signal success (disk usage is below threshold), send an HTTP request to the Ping URL directly:
curl https://hc-ping.com/your-uuid-hereAnd, to signal failure, append “/fail” at the end of the Ping URL:
curl https://hc-ping.com/your-uuid-here/failLet’s integrate this into our monitoring script:
url=https://hc-ping.com/your-uuid-here
pct=$(df --output=pcent / | tail -n 1 | tr -d '% ')
if [ $pct -gt 75 ]; then url=$url/fail; fi
curl -fsS -m 10 --retry 5 -o /dev/null --data-raw "Used space on /: $pct%" $urlThe curl call here has a few extra arguments:
- “-fsS” tells curl to suppress output except for error messages
- “-m 10” sets a 10-second timeout for HTTP requests
- “–retry 5” tells curl to retry failed requests up to 5 times
- “-o /dev/null” sends the server’s response to
/dev/null - “–data-raw …” specifies a log message to include in an HTTP POST request body
Save this script in a convenient location, for example, in /opt/check-disk-space.sh, and make it executable. Then edit crontab (crontab -e) and add a new cron job:
*/10 * * * * /opt/check-disk-space.shCron will run the script every 10 minutes. On every run, the script will check the used disk space, and signal success (disk usage below or at threshold) or failure (disk usage above threshold) to Healthchecks.io. Whenever the status value flips, Healthchecks.io will send you a notification:
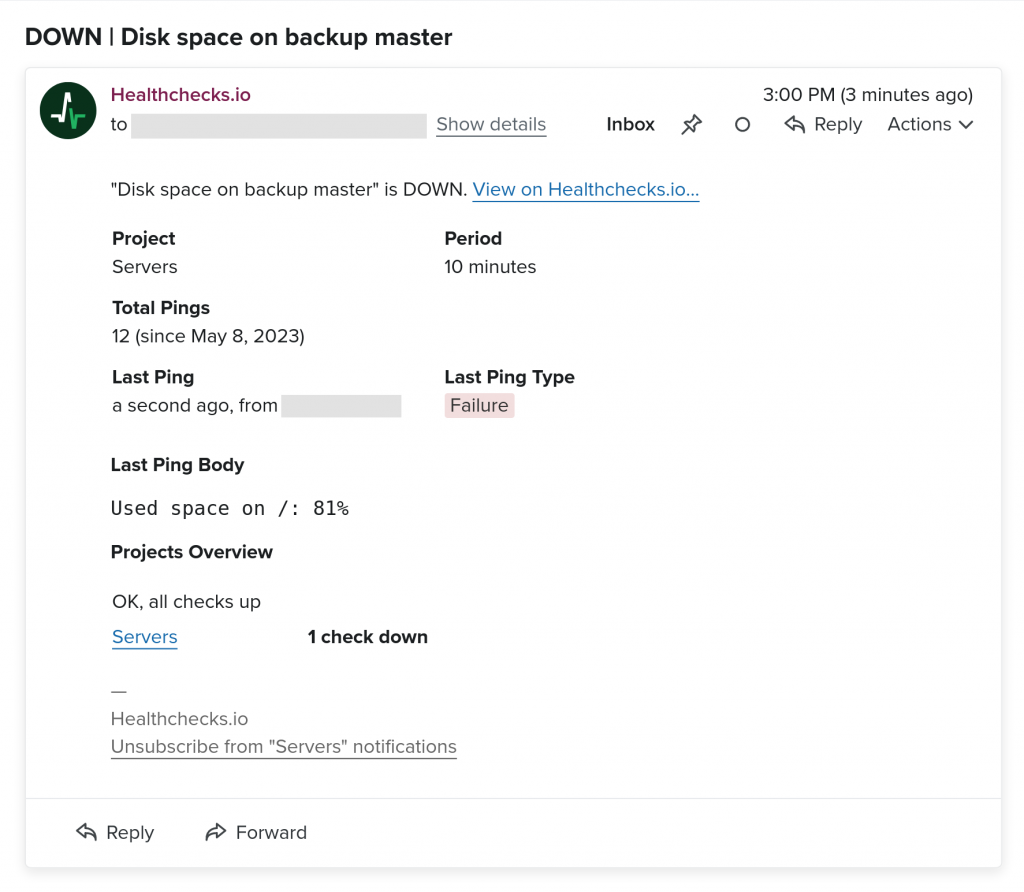
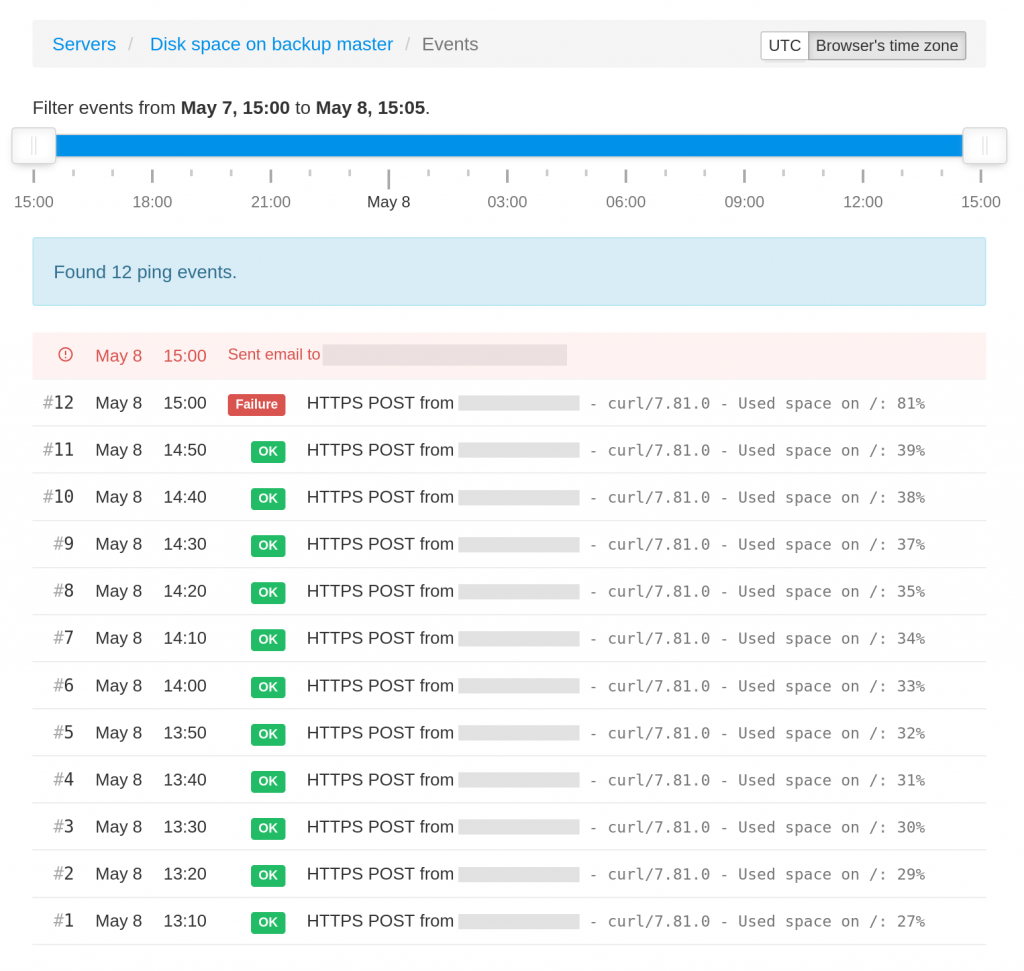
You will also see a log of the monitoring script’s check-ins in the Healthchecks.io web interface:
Closing Comments
If your use case involves handling millions of small files, at least on ext4 filesystems, the filesystem can also run out of inodes. Run df -i to see how many inodes are in use and how many are available. If inode use is a potential concern, you could update the check-disk-space.sh script to track it too.
The shell script + Healthchecks.io pattern would work for monitoring other system metrics too. For example, you could have a script that checks the system’s 15-minute load average, the number of files in a specific directory, or a temperature sensor’s reading.
If you are looking to monitor more than a couple of system metrics though, look into purpose-built system monitoring tools such as netdata. The shell script + Healthchecks.io approach works best when you have a few specific metrics you care about, and you want to avoid installing full-blown monitoring agents in your system.
Thanks for reading and happy monitoring,
–Pēteris.