On February 7, Healthchecks.io experienced an issue with sending notifications. An invalid cron expression slipped into the system, which caused the notification sending jobs to crash and restart in a loop. Timeline (all times are in UTC, and from February 7):
- 0:37: a check with a bad cron schedule gets created via API
- 0:41: the check receives its first ping
- 0:42: one minute later, the notification senders go into a crash-restart loop
- 1:02: external monitoring alerts go out
- 7:00: I’ve woken up and found out about the outage
- 7:28: The invalid cron expression is located and fixed, notification sending resumes
- 7:52: I post a tweet about the outage
- 10:00: Deployed mitigations for the “sendalerts” process repeatedly crashing, and stricter cron expression validity checks
This outage started at in the middle of night (2:42 AM local time) and so it took several hours until I found out about it and could jump on to fixing it. During this time, Healthchecks.io was not sending out any notifications (all types: emails, webhooks, Slack alerts, …). On the positive side, the web dashboard, the ping endpoints, the API and the badges were working normally.
After fixing the bad cron schedule, the notification senders resumed work and quickly went through the backlog of unsent notifications:
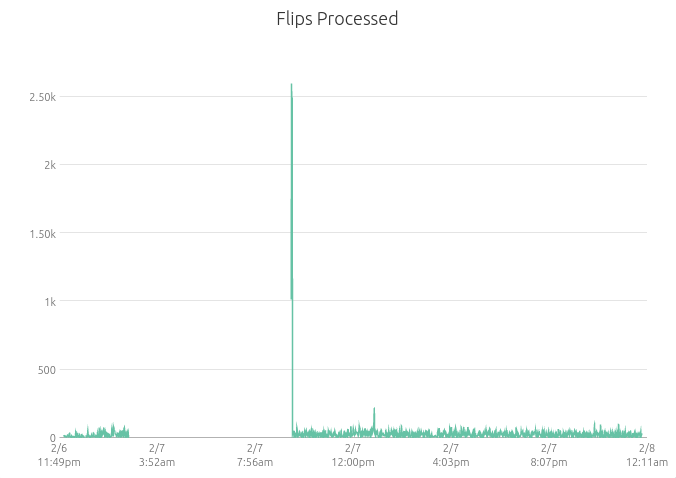
When notification sending resumed, Healthchecks.io sent out notifications for all checks that had flipped their state once (from “up” to “down”, or from “down” to “up”) during the outage. Unfortunately, it would have missed cases where a check flips twice (for example, “up” → “down” → “up”) during the outage window. If a check went down but came right back up during the outage window, Healthchecks.io missed it and didn’t send a notification.
The Root Cause
The “sendalerts” crash loop was tripping on the following cron schedule: “0 0 31 2 *”. Or, in human words, “at midnight of every February 31st“. The notification sender was crashing while calculating the next expected ping time for this schedule.
The Fix
- To get around the immediate crashing problem, I manually edited the problematic cron schedule
- In the “sendalerts” management command I added a mitigation for repeatedly crashing on the exact same check. With the mitigation, “sendalerts” postpones the problematic check for 1 hour, so it can process other checks in the meantime.
- I added extra validation step for cron expressions. Healthchecks now makes sure it can calculate a valid “next ping time” for a cron expression before allowing it into the system.
- When the outage started, I received monitoring alerts from three different services. All three alerts went to email, and I didn’t notice them until the morning. I’ve now updated notification settings to also receive Pushover notifications with the “Emergency” priority. These notifications override phone’s Do Not Disturb settings and repeat until acknowledged.
I apologize to all Healthchecks.io users for any inconvenience caused.
– Pēteris Caune,
Healthchecks.io