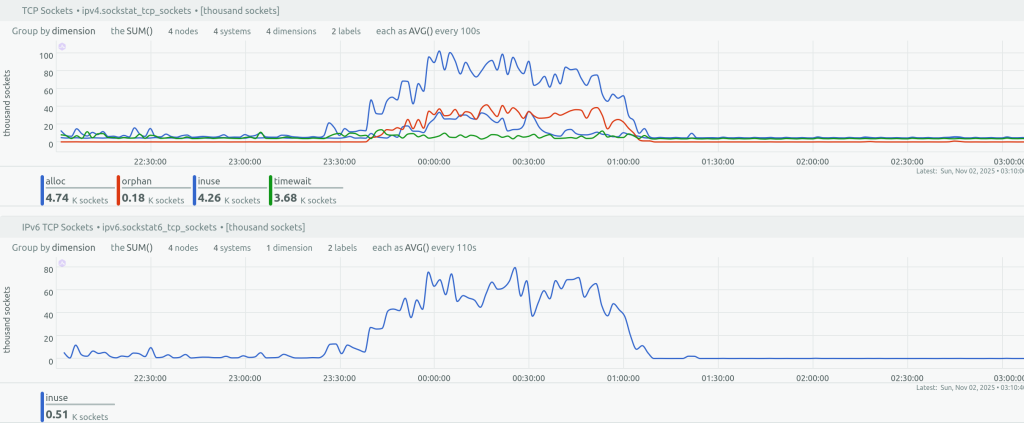
Between November 1, 23:30 UTC and November 2, 1:10 UTC, Healthchecks.io (both the main website, healthchecks.io, and the ping endpoints, hc-ping.com) had intermittent connectivity issues in the form of some requests taking multiple seconds to finish, or timing out entirely. Usually, such symptoms are caused by infrastructure problems out of our control, but this time the problem was on our side: our load balancers were running out of available connection slots. Our load balancers were dealing with a flood of ping requests from a misconfigured client. The load balancers were using the “tarpit” rate-limiting to slow the client’s requests down. Unfortunately, this did not work as intended: the client did not slow down, but the load balancers were hitting their connection count limits and rejecting legitimate requests.
Timeline
- November 1, 23:24 UTC: ping requests for a single, specific UUID increase from 10 requests/second to sustained 300 requests/second.
- November 1, 23:39 UTC: one of the load balancers starts rejecting connections and gets automatically removed from DNS rotation. This increases the load on the remaining load balancers and starts a chain reaction.
- November 2, 00:11 UTC: I get woken up by blaring notifications and start an investigation.
- November 2, 01:06 UTC: I have identified the offending client IP addresses (a single IPv4 address and a /64 IPv6 subnet), and update the load balancer configuration to reject TCP requests from them. Things go back to normal.
- November 2, 08:40 UTC: To avoid similar issues in the future, I update the load balancer rate-limiting configuration to return HTTP 429 immediately and not use the “tarpit” method.
Tarpit
Healthchecks.io uses multiple levels of rate-limiting to prevent a ping flood from overloading our database:
- On load balancer servers, HAProxy applies the initial, lax rate limiting. It proxies the good requests to NGINX running on application servers.
- On application servers, NGINX applies more strict rate limiting and geo-blocking. It proxies the good requests to the application.
When a client exceeds the configured rate limit, HAProxy gives several options on how to handle the client’s request:
- Deny (
http-request deny): return a HTTP 429 “Too Many Requests” response to the client. - Tarpit (
http-request tarpit): wait for a bit, and only then return HTTP 429 to the client. During the wait period, a network socket is tied up. - Silent drop (
http-request silent-drop): immediately disconnect without notifying the client, so the client continues to wait. - Reject (
http-request reject,tcp-request content reject, andtcp-request connection reject): immediately disconnect, but do not force the client to wait.
Each method has its pros and cons.
- “Deny” is the most polite, but also the most expensive in case of an attack. For each request, the server has to do a full TLS handshake, parse the HTTP request, and send an HTTP response.
- “Tarpit” can slow down clients that make requests sequentially, but can overwhelm the load balancer if clients make huge amounts of requests in parallel.
- “Silent drop” forces the client to wait and does not tie up the server’s resources, but may be too aggressive in cases where the client is merely misconfigured and not intentionally malicious.
- “Reject” is cheaper to process than “Deny” but does not inform the client about why the connection was rejected.
Our HAProxy servers were configured to use the tarpit method to rate-limit particularly spammy clients. To reduce the risk of running out of connection slots, the wait time was set to 1 second. Unfortunately, in this case, the waiting period did not slow the client down, and the request rate was high enough that the HAProxy servers did indeed start to hit the connection slot limits.
The Fix
After figuring out what was happening, my immediate fix was to block the specific offending IP addresses using the “Reject” method. Later in the day, after gaining a better understanding of the problem, I updated the HAProxy configuration to use the “Deny” method to reject rate-limited requests. One more lesson learned.
Update on November 5, 2025
In the past couple of days, I have made a few additional changes in addition to switching away from using the “tarpit” method:
- In the HAProxy configuration I added previously missing
timeout http-request 5s. This guards against Slowloris attacks. This outage was not caused by a Slowloris attack (in fact, it was more like a “reverse Slowloris”: the server, rather than the client, was adding the pauses), but Slowloris attacks can also cause connection slot exhaustion, and are easy to perform. - I increased the
maxconnparameter in HAProxy configuration to give the load balancers some more breathing room. - I updated the rate-limiting rules to cover both hc-ping.com and hchk.io endpoints (previously, only hc-ping.com was being rate-limited at the load balancer level).
- I added a new alerting rule in Netdata agents to notify me when the number of active HAProxy frontend sessions passes specific thresholds (well below the
maxconnvalue). - I tweaked the HAProxy logging format to make the logs easier to use.
I am sorry for the false monitoring alerts and the confusion caused by this incident.
–Pēteris