On April 30, starting from 15:46 UTC, Healthchecks.io was unavailable for about 30 minutes. The outage was caused by, most likely, hardware instability on the database server. The PostgreSQL server crashed with a segfault, and a little later, the entire server stopped responding to pings. The system recovered after a manual reboot. Afterward, I migrated the database to new hardware to reduce the chance of a similar incident in the future.
Timeline
- April 30, 15:30: Netdata monitoring shows first deviations from steady state in temperature, CPU usage, and IO activity on the database server.
- April 30, 15:36: PostgreSQL logs a segfault in system logs.
- April 30, 15:46: The database server completely locks up. I start receiving monitoring notifications but am away from my work computer.
- April 30, 16:05 I arrive at the work computer and trigger a hardware reset on the database server. The server boots back up and resumes operation.
- May 1, 7:00: I provision and start setting up replacement database servers (both primary and standby).
- May 2, 7:25: I fail-over to the replacement database server.
Immediate Response
When monitoring notifications started, I was at a playground with kids, about 15 minutes away from my main work computer. I had a laptop with deployment tools with me. The tools were not fully up to date, and I decided it was safer and not much slower to drive back to the main work computer.
After arriving at the main computer and finding out the database server does not respond to pings, I triggered a hardware reset for it. The alternative option was immediately promoting the standby server as the new primary. Trying a reboot first could cost time and extend the outage if it didn’t work, but would be safer if it did work. At this point, I didn’t know yet if the control plane worked and if I could disable the old primary reliably. The old primary coming back before its IP is removed from client DB configurations would get the system in a split-brain scenario.
Investigation
System logs showed a segfault (timestamps are UTC+2):
Apr 30 17:36:40 db3 kernel: postgres[2431248]: segfault at 0 ip 0000000000000000 sp 00007fff179fb4e8 error 14 in postgres[589f9d235000+dc000] likely on CPU 6 (core 12, socket 0)
Apr 30 17:36:40 db3 kernel: Code: Unable to access opcode bytes at 0xffffffffffffffd6.After reboot, “smartctl -a” showed no logged NVMe drive errors on either of the two drives. “cat /proc/mdstat” showed both RAID drives being up and healthy.
Netdata graphs showed various anomalies that started about 15 minutes before the complete system lock-up. Here’s a graph showing CPU temperatures jumping and NVMe temperatures dropping about 10 minutes before the lock-up (timestamps are UTC+3):
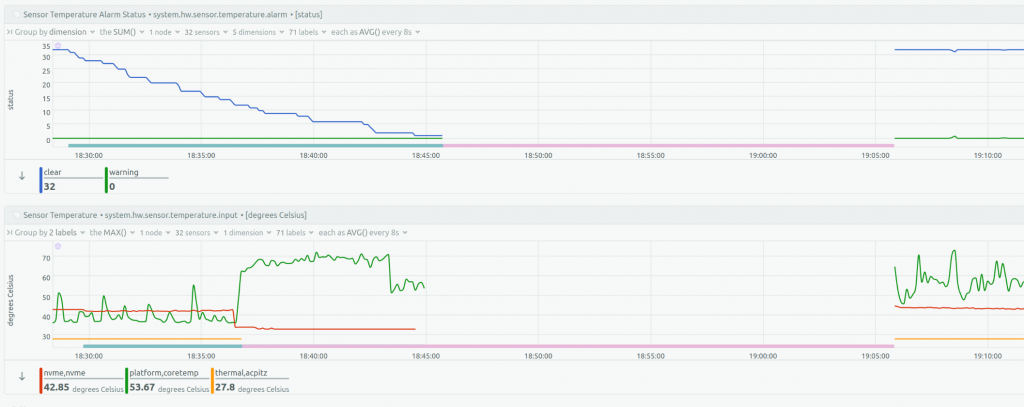
My assumption is that the underying cause was hardware instability. I didn’t spend too much time looking for the exact cause but instead focused on preparing a replacement server, as debugging and experimenting with a live production machine was not an appealing option.
Migration to New Hardware
Healthchecks.io runs on Hetzner bare metal servers. The old database servers, primary and standby, were running on EX101 machines: Intel Core i9-13900, 64GB ECC RAM, and 2×1.92TB NVMe drives. I wanted different hardware, different in as many aspects as possible, and selected EX130-S:
- CPU: Intel Xeon 5412U, presumably and hopefully higher quality than consumer-class Intel Core i9.
- RAM: 128GB ECC RAM. Higher capacity, so there is a chance the RAM sticks are a different model.
- Storage: 2×3.84TB NVMe. Higher capacity, so guaranteed different model than EX101.
I baked the servers with stressapptest for two hours and verified no corrected ECC errors. I then installed OS and used my existing deployment scripts to set up PostgreSQL and start data replication. After a day of operation and monitoring, which showed no issues, I performed a DB fail-over to one of the new servers.
In Closing
In the current hosting setup, the database is a single point of failure. If a web server fails, the load balancers remove it from rotation in a couple of seconds. If a load balancer fails, a watchdog service removes it from DNS rotation, and DNS changes propagate in a couple of minutes. But if the primary database fails, I have to fix it manually. I am still not confident I can make an automatic fail-over process that handles all the partial outage cases better than a manual process. Therefore, my aim is to make database outages as infrequent and short as possible.
–Pēteris