
Healthchecks.io recently got a new feature: run IDs.
RID=`uuidgen`
# Send a "start" signal, specify ?rid query parameter
curl https://hc-ping.com/your-uuid-here/start?rid=$RID
# ... do some work here ...
# Send a "success" signal, specify the same ?rid value
curl https://hc-ping.com/your-uuid-here?rid=$RID
Run IDs are client-chosen UUID values that the client can optionally add as a “rid” query parameter to any ping URL (success, /start, /fail, /log, /{exitcode}).
What are run IDs useful for? Healthchecks.io uses them to group events from a single “run”, and calculate correct run durations. This is most important in cases where multiple instances of the same job can run simultaneously, and partially or fully overlap. Consider the following sequence of events:
- 12:00 start
- 12:01 start
- 12:05 success
- 12:06 success
Without run IDs, we cannot tell if the second success event corresponds to the first or the second start event. But with run IDs we can:
- 12:00 start, rid=05f4aa48…
- 12:01 start, rid=7671e111…
- 12:05 success, rid=05f4aa48…
- 12:06 success, rid=7671e111…
The usage of run IDs is completely optional. You don’t need them if your jobs always run sequentially. If you do use run IDs, make sure that:
- the rid values are valid UUIDs in the canonical text form (with no curly braces, with no uppercase letters)
- you use the same rid value for matching start and success/fail events
Healthchecks.io will show the run IDs in a shortened form in the “Events” section:
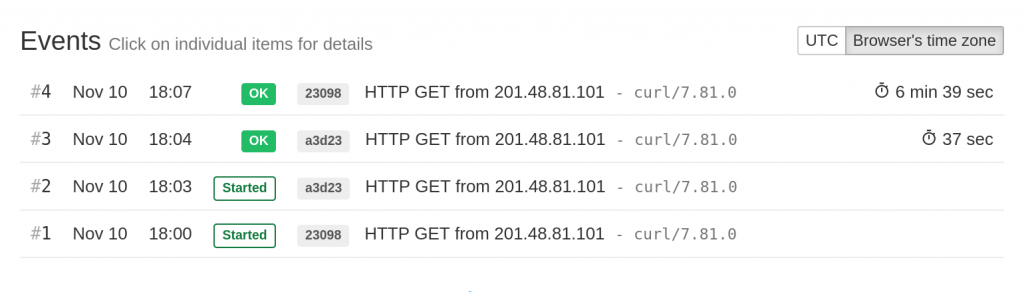
In the above image, note how the execution times are available for both “success” events. If the run IDs were not used, event #4 would not show an execution time since it is not directly preceded by a “start” event.
Alerting Logic When Using Run IDs
Healthchecks.io monitors the time gaps between “start” and “success” signals: if a job sends a “start” signal, but then does not send a “success” signal within its configured grace time, Healthchecks.io will assume the job has failed and notify you. However, if multiple instances of the same job run concurrently, Healthchecks.io will only monitor the run time of the most recently started run and alert you when it exceeds the grace time. Under the hood, each check tracks a single “last started” value, which gets overwritten with every received “start” event.
To illustrate, let’s assume the grace time of 1 minute, and look at the above screenshot again. Event #4 ran for 6 minutes 39 seconds and so overshot the time budget of 1 minute. But Healthchecks.io generated no alerts because the most recently started run finished within the time limit (it took 37 seconds, which is less than 1 minute).
Happy monitoring!
–Pēteris