When clients make HTTP POST requests to ping URLs, Healthchecks captures and stores request body data. You can use this feature to log a command’s output and have it available for inspection later:
$ cowsay hello | curl --data-binary @- https://hc-ping.com/some-uuid-hereSame thing, using runitor instead of curl:
$ runitor -uuid some-uuid-here -- cowsay helloYou can view the request body data in the web UI:
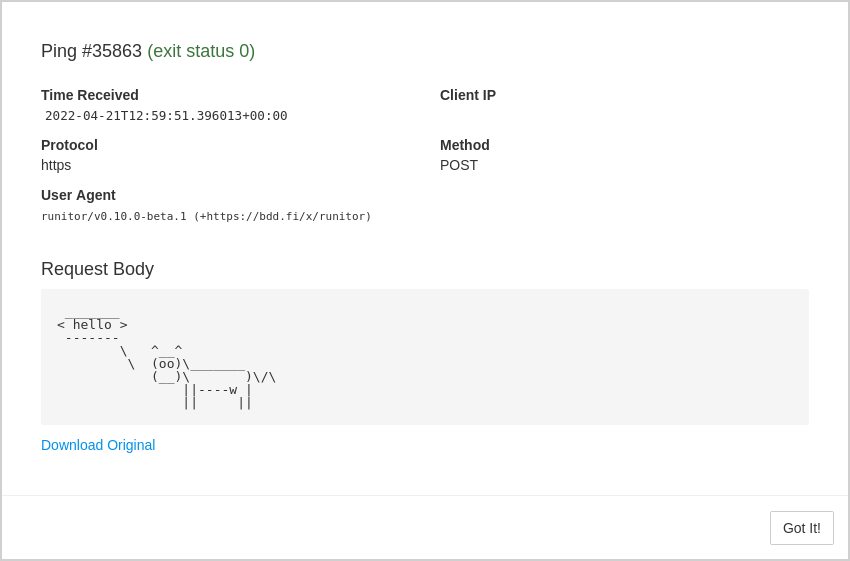
Healthchecks also captures and stores email messages, when pinging by email:
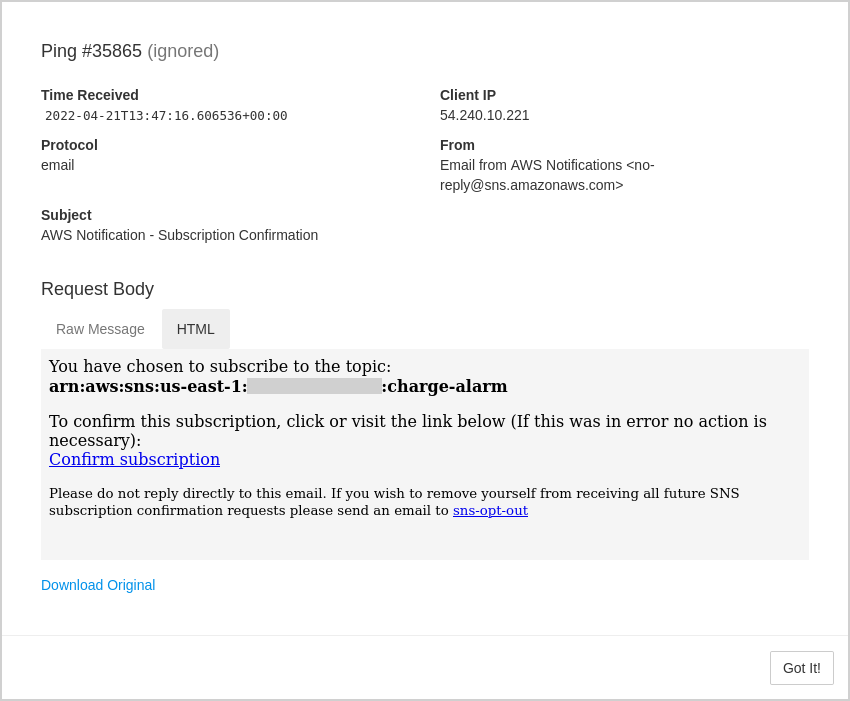
There is a limit to how much data gets stored. The limit used to be 10KB. For example, if a client sends 50KB in an HTTP POST request body, Healthchecks would store the first 10KB, and ignore the remaining 40KB. I recently bumped up the size limit to 100KB. Users can now attach 10x more log information to every HTTP POST request, and HTML-heavy email messages are now less likely to get chopped off in the middle.
In theory, the limit change could have been as simple as adding one zero to a configuration parameter, but in practice, there was a little bit more to it!
Database vs S3
Healthchecks used to store request body data in its primary and only data store, a PostgreSQL database. Bumping up the limit and throwing more data in the database would work in the short term, but would create problems in the long run. Backup sizes and processing times would grow at a quicker rate. Network I/O to the database server would also increase, and sooner become a bottleneck.
Now, how about outsourcing ping body storage to AWS S3? This would allow bumping up the size limit without ballooning the database size (yay!). On the other hand, this would add a new moving part to the system, and increase code and operational complexity (oh no!). But perhaps still worth it?
Healthchecks would be doing lots of small S3 PUT requests, and AWS S3 has per-request fees. Quick napkin math: AWS charges $0.005 per 1000 PUT requests. Let’s say we’re uploading 20 objects to S3 per second. That’s 20 * 60 * 60 * 24 * 30 = 52M PUT requests per month, or $260 added to the AWS bill. AWS also charges for bandwidth and storage. And what about Schrems II? There could be personal data in ping bodies, so we would need to encrypt them before handing them off to AWS.
Luckily there are alternate, S3-compatible object storage providers, some of them based in the EU, and some of them charge no per-request fees! Scaleway and OVH looked like two promising candidates.
Sync vs Async Uploads
OK, let’s dive into implementation decisions. When Healthchecks receives a ping, should it upload request body data to S3 right away, in the HTTP request-response cycle? Or should it stash the request body data somewhere and have a background process deal with the uploads?
The synchronous approach is simple operationally (no background processing to worry about), but the S3 upload operations can slow down the request-response cycle.
The async approach is more fiddly to set up. The background worker process can throw an exception or grow a backlog of jobs, it needs to be monitored. On the upside, any S3 API hiccups or slowdowns would not affect the ping handler’s throughput.
Easy solution–I implemented both methods! The open-source Healthchecks project uploads ping bodies synchronously. But on the hosted service (healthchecks.io), the ping handler stores received pings on the filesystem, and a separate worker process picks them up and uploads them to S3.
Homegrown API requests vs S3 Client Library
Moving forward, how does one upload an object to an S3 bucket? I’ve used boto3 in the past, but how hard could it possibly be to send the right payload to the right API endpoint?
Well, by the time I got a small request signing experiment to work, I decided I’ll use a library after all! I picked minio-py as the S3 client library. It is smaller and has fewer dependencies than boto3.
Upgrade From Storing Strings to Storing Bytes
If the ping body is just a few bytes in size, does it still make sense to offload its storage to S3? Probably not. There should be some threshold value (say, 100 bytes), below which ping bodies still get stored in the database.
Any data that we put or retrieve from object storage we will treat as binary. But the “body” field in the Healthchecks database has historically been a text field, only appropriate for storing Unicode strings.
To avoid the inconsistency of storing short ping bodies as Unicode strings, and longer ping bodies as binary data, I added a new “body_raw” binary field in the database and updated the application code to use it by default.
Object Key Naming Scheme
What naming scheme to use for keys in the S3 bucket? The most straightforward naming scheme would be /<uuid>/<n>:
/504eb741-1966-49fe-a6e7-4d3133d2b2bd/1/504eb741-1966-49fe-a6e7-4d3133d2b2bd/2/504eb741-1966-49fe-a6e7-4d3133d2b2bd/3- …
/504eb741-1966-49fe-a6e7-4d3133d2b2bd/100/504eb741-1966-49fe-a6e7-4d3133d2b2bd/101- …
Here “uuid” would be the unique UUID of a check, and “n” is the serial number of the received ping: “1” for the first received ping, “2” for the second received ping, and so on.
Now, let’s say we are cleaning up old objects and want to delete all objects with uuid=504eb741-1966-49fe-a6e7-4d3133d2b2bd and n<50. How to do that? With the above naming scheme, we could:
- Retrieve a list of all objects with the prefix
/504eb741-1966-49fe-a6e7-4d3133d2b2bd/. - Filter the list, keeping only the entries with n<50
- Then run the DeleteObjects API call and pass the filtered list to it.
I noticed the list_objects call has an optional start_after argument, perhaps it can be used to avoid the client-side filtering (step 2)?
Yes, it can – if we add specially crafted sorting prefixes to the object keys:
/504eb741-1966-49fe-a6e7-4d3133d2b2bd/zi-1/504eb741-1966-49fe-a6e7-4d3133d2b2bd/zh-2/504eb741-1966-49fe-a6e7-4d3133d2b2bd/zg-3- …
/504eb741-1966-49fe-a6e7-4d3133d2b2bd/xijj-100/504eb741-1966-49fe-a6e7-4d3133d2b2bd/xiji-101- …
If we want all keys with n<50, we can now do:
list_objects(prefix="504eb741-...-4d3133d2b2bd/", start_after="yej")Exercise time: looking at just the above examples, can you work out how the zi, zh etc. prefixes are generated, and why this works?
If you are interested, here is the function that generates the sorting prefix.
Boolean Serialization Issue
I ran into an issue when using the minio-py’s remove_objects call: when generating a request XML, it was serializing boolean values as True and False, instead of true and false. When testing, this was accepted by AWS S3 API, but both Scaleway and OVH were rejecting these requests as invalid.
- I filed an issue with minio-py, and they fixed the code to serialize boolean values to lowercase strings.
- I reported the issue to Scaleway and OVH, both fixed their S3 implementation to accept capitalized boolean values.
Object Storage Cleanup
Let’s say a user is closing their Healthchecks account, and we want to delete their data. With Django and relational databases, it is remarkably easy to do:
user.delete() # that's itDjango will delete the user record from the auth_user table, and will also take care of deleting all dependent objects: projects, checks, channels, pings, notifications, etc. All of that, with one line of code!
For the S3 object storage though we will need to take care of data cleanup ourselves. I wrote a pruneobjects management command which iterates through the S3 bucket and removes all objects referencing checks that do not exist in the database anymore.
Testing Object Storage Providers
I initially planned to use Scaleway Object Storage. I contacted their support and got a confirmation that my planned use case is reasonable. As I was using Scaleway to test my work-in-progress code, I saw their DeleteObjects API calls were rather slow. They would often take seconds, and sometimes tens of seconds to complete. Around that time Scaleway object storage also happened to have a multi-hour outage. API calls were returning “InternalError” responses, the dashboard was not working.
I switched my focus to OVH. Same as with Scaleway, I contacted OVH support and described my use case and planned usage patterns. I explicitly asked about API request rates, they said–no limits. I set up the account and got busy testing. The API operations seemed significantly quicker. DeleteObjects would typically complete in a sub-second.
I did run into several hopefully teething troubles with OVH too. API would sometimes return “ServiceUnavailable, Please reduce your request rate.” OVH would acknowledge the issue with this masterpiece of an explanation:
The problem you have encountered is due to occasional operations that have taken place on the platform.
When the number of objects in the bucket went above 500’000, OVH dashboard couldn’t display the bucket’s contents anymore. The page would take a long time to load and eventually display “Internal server error”. This issue has not been resolved yet. But the API works.
“Ping Body Not Yet Available” Special Case
If ping bodies are being uploaded asynchronously, we can run into a situation where we want to show the ping body to the user, but it is still sitting in a queue, waiting to be uploaded to S3. Here’s an example scenario:
- Client sends a “fail” event with data in the request body.
- Ping handler registers the ping and adds the body data to the upload queue.
- Milliseconds later, the “sendalerts” process sees the failure and prepares an email notification. It needs the ping body, which is not present in the S3 bucket yet.
Note that the ping handler and sendalerts may be running on different machines, so sendalerts cannot peek in the upload queue either.
My “good enough” solution for this was to add a conditional delay to the email sending logic:
- Fetch the request body from S3.
- If not found, wait 5 seconds, then fetch it again.
- If still nothing, use a “The request body data is being processed” fallback message in the email.
The idea here is that request bodies usually upload quickly. Assuming normal operation and no significant backlog, 5 seconds should be plenty. But if the request body is still not available after the 5 seconds, we don’t want to delay the email notification too much, and use the fallback message.
S3 Backup
In theory, OVH claims a 100% resilience rate for their object storage service. But we know entire data centers can and sometimes do burn down, and ultimately it is our responsibility to be able to recover the data. My S3 backup solution is a cron job on a dedicated VPS, doing the following:
- Download entire contents of the bucket using “aws s3 sync”.
- Pack the files together using
tar, encrypt them withgpg, and upload the resulting file to a different bucket at a different provider.
#!/bin/bash
SRC_ENDPOINT=https://s3.sbg.perf.cloud.ovh.net
BUCKET=***
TIMESTAMP=`date +"%Y%m%d-%H%M%S"`
DST_PATH=s3://***/objects-$TIMESTAMP.tar.gpg
set -e
runitor -uuid *** \
-- aws --profile src --endpoint-url $SRC_ENDPOINT s3 sync s3://$BUCKET $BUCKET --delete
tar -cf - $BUCKET | gpg --encrypt --recipient 832DDD6E | aws --profile dst s3 cp - $DST_PATHThe “aws” command is provided by the awscli tool. s3cmd also has a “sync” command, but in my testing, it could not handle a bucket with hundreds of thousands of objects.
The “n % 50 == 0” Bug
As I was working on implementing S3 backup, I noticed that the bucket contains more data than I was expecting. Some checks had 8000 and more ping bodies stored. How?
The cleanup logic for asynchronous uploads is:
- Pick a ping body from the queue, upload it to S3.
- If the ping’s serial number is divisible by 50, run a cleanup routine.
The idea is to run the cleanup routine every 50 pings. Now, what happens if the client sends alternating “start” events as HTTP GET requests, and “success” events as HTTP POST with a request body? We can have a situation where every POST has an odd serial number, and so our cleanup routine never runs! My “good enough” fix here was to change the constant “50” to a non-even number.
The 10KB to 100KB Limit Increase
With the above in place, I added OVH to the list of sub-processors in the Privacy Policy, increased the ping body limit to 100KB and gradually rolled out the changes to production servers. After several days of testing to see if everything is coping well, I announced the limit increase on Twitter.
Here are graphs from Netdata showing the object uploads per second, and the backlog size, aggregated across all web servers:
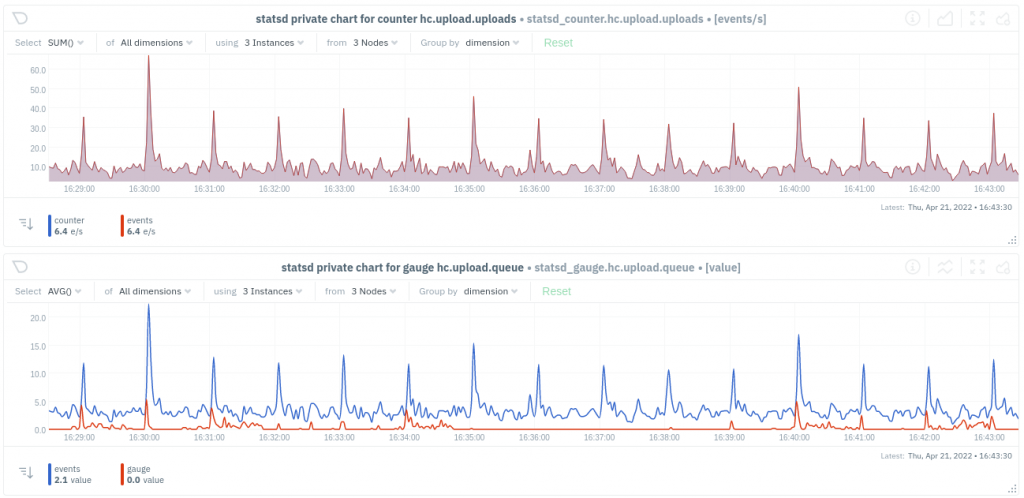
And that’s how “we” moved some data to S3. Thanks for reading!
–Pēteris.