Foreword: In May this year, I had the honour to speak at PyCon Lithuania about Healthchecks. Having practically no public speaking experience, I prepared carefully. As a part of the preparation, I had the whole speech written out. This saved me from lots of awkwardness during the talk, but also makes it easy to share the final version here in a readable form. Below are the slides and the spoken text from my talk “Building an Open-source Django Side-project Into a Business” at PyCon Lithuania 2019. Enjoy!

Hello, my name is Pēteris Caune, I am happy to be here at PyconLT and this talk is about my side-project – written in Python – it’s called Healthchecks.

I will talk about my motivation for building Healthchecks, and about some of the notable events and challenges, about the project’s current state, how things have worked out so far, and future plans.
Before we get into it, here’s the current status of the project. Healthchecks is almost 4 years old. It has a bunch of paying customers and it comfortably covers its running costs. But – it is not yet paying for my time. Basically, currently Healthchecks is a side project, and the medium term plan is for it to become a lifestyle business. Keep this in mind as a context – with this project, I’m not focusing on profitability and am fine with it growing slowly. For instance, I’m not using aggressive marketing and aggressive pricing. If in your project you do need to be as profitable as possible, as soon as possible, you will want to do a few things differently than me.
So, with that in mind, let’s go!

Healthchecks is a Django app for monitoring cron jobs on servers. It uses the Dead Man’s hand principle: you set up your cron job or background service to make small, simple HTTP requests to the Healthchecks server.
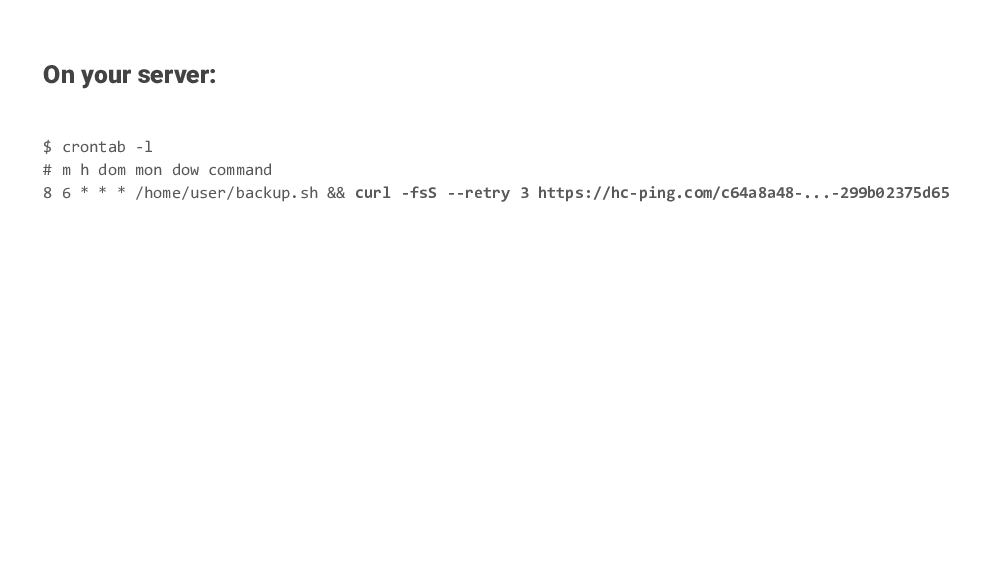
Each HTTP request is like a message saying “I’m still alive!”, it is a sort of a heartbeat.
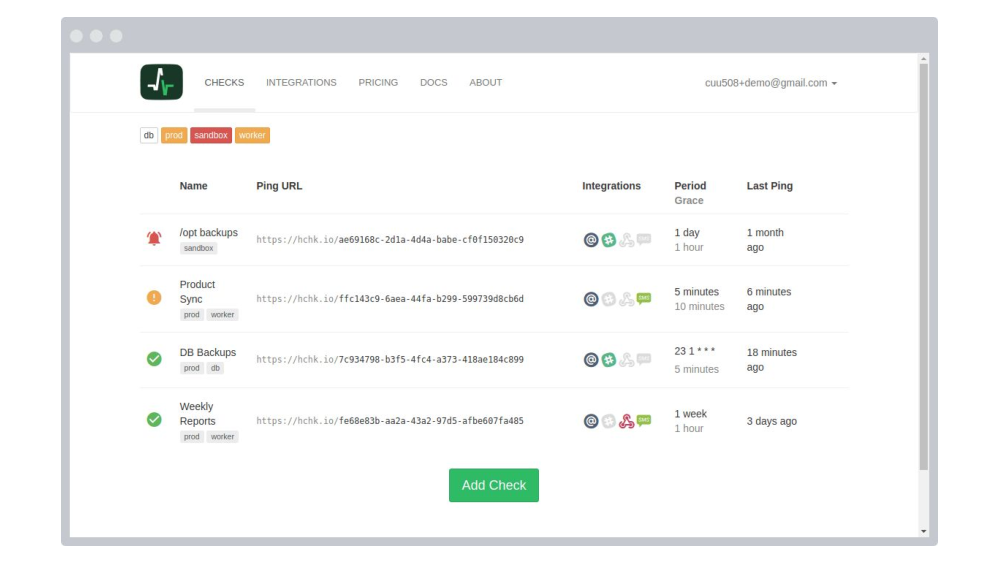
The Healthchecks server looks for these “heartbeat” messages.

And it sends you alerts when they don’t arrive at the expected time. That’s the basic idea. And it’s a simple idea and I was not the first one to think of it.
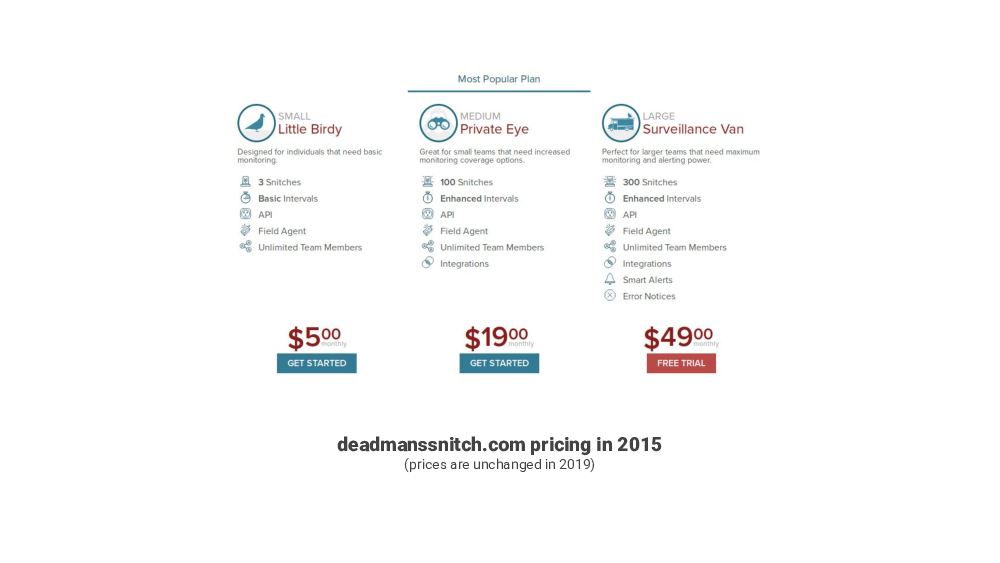
About four years ago, in 2015 I was looking for a tool like this. And I found two services, that already existed, DeadMansSnitch and, recently launched, Cronitor.
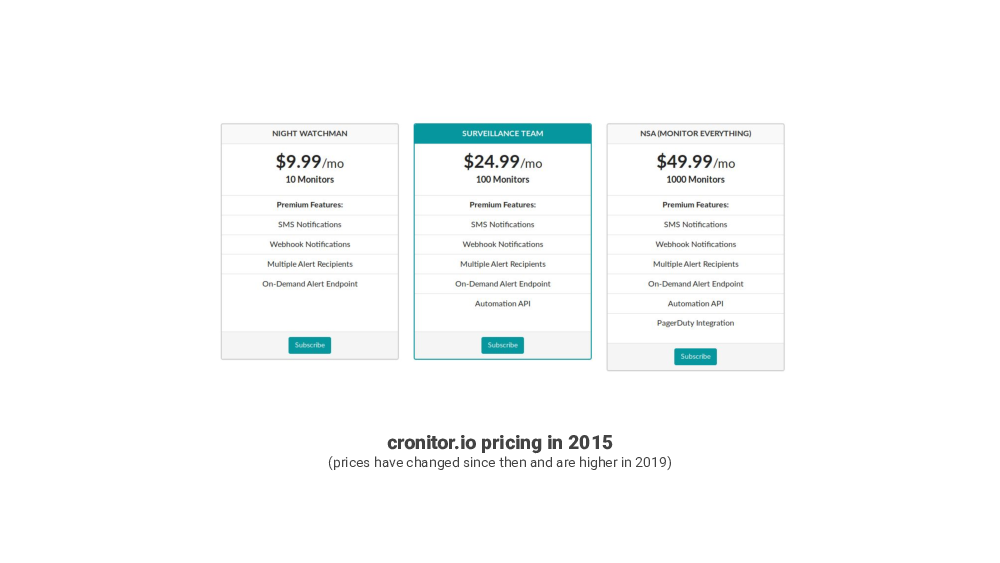
They looked good, but they seemed pricey, and I could not justify paying for them for the types of things I wanted to monitor at the time.
So I was bouncing around this idea for a while – “maybe I just build this myself…?” In June 2015 I started to hack on it and made the first git commits. It seemed like a fun thing to work on. I liked how conceptually simple the basic idea was.

I set a slightly ambitious goal to build a service that works as well or better than the existing services, and is offered for free or for significantly cheaper. This was the challenge: I was not interested in just cloning Dead Mans Snitch or Cronitor, and having similar pricing, and just competing with them.
Another aspect of motivation for this was: In my day job as a full stack developer I do have certain amount of influence on the various decisions. But, ultimately, I’m working on somebody else’s product. And I must be careful not to get emotionally attached to my work and its fate.
Now, with Healthchecks, I would have full control over what this thing becomes. And I would be in charge of everything: product design, UI design, marketing activities or lack thereof, customer support – talking with customers directly, taxes and legal stuff. These are the types of things that I don’t normally do as a developer.
So this would require me to get out of the comfort zone, face new challenges and learn new skills, which is good. By the way, me talking here at PyconLT is also a form of such a challenge: public speaking! I’m an introverted person – so, ya – this is a challenge!
Another line of thought was – even if the project doesn’t go anywhere, it would look good on my CV, and be useful that way.
So, that’s the motivation.
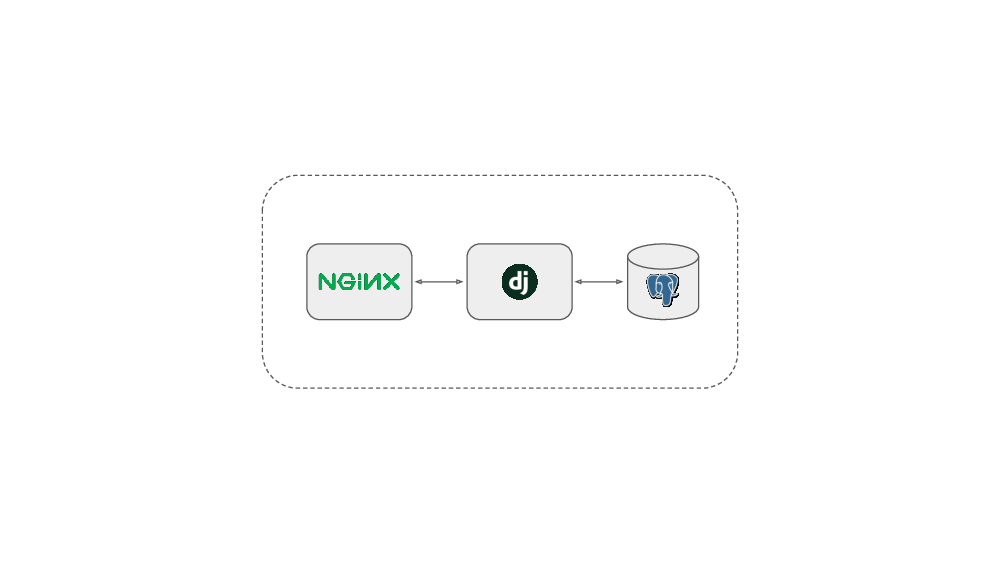
Healthchecks uses Django framework. I chose Django because I was already familiar with it. I knew I would be immediately productive. I started with a simple setup: a Django web application and a Postgres database and almost nothing more. My plan was to try to keep it as simple as possible and see how far I could get without complicating it with additional components. I set out to get the basic functionality working, then work on polishing the UI and, basically, see where it goes.
So, June 2015, I made the first commit to a public Github repository. I decided to make this open source to differentiate from existing competitors. Also, developing this in the open would be a little bit like a reality show – everyone can see how my work is progressing, and how crappy or not crappy my code is. Sounds fun, right?
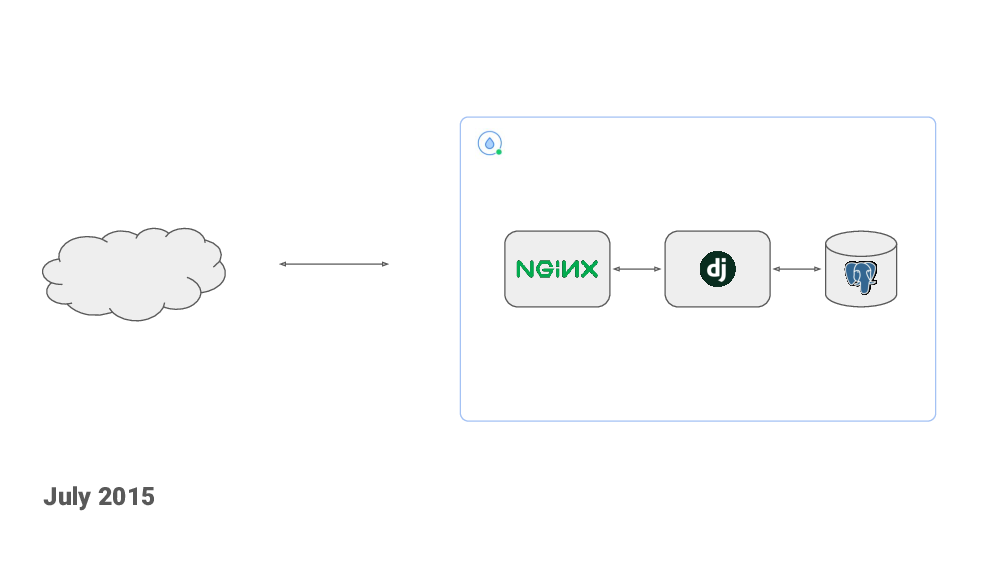
A month later I deployed the code to a $5/mo DigitalOcean droplet, I bought the healthchecks.io domain and an SSL certificate. I made a “Show Hacker News” post (which did not go anywhere). And, like that, the project was live!
Later in 2015, I made a blog article about some technical aspects of the project, and submited it to Hacker News, of course, and this one did get on the front page and brought in a good amount of visitors. Both the webapp and the database was still on a single DigitalOcean droplet, but I had moved it up to a $20/mo in anticipation of traffic.
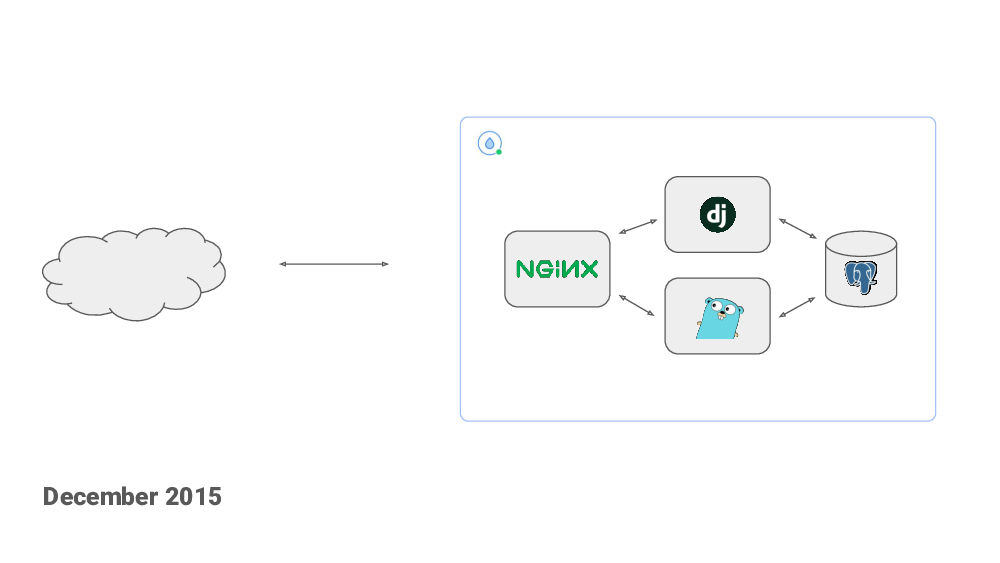
Six months in, I started to see server’s CPU usage climbing. CPU was mostly being spent handling the pings – the incoming HTTP requests sent from the cron jobs. These are simple requests but the volume was steadily going up. I used this as an excuse to learn a little bit of go-the-language and I wrote the ping handler in Go. It had a significantly smaller per-request overhead compared to Django.
My naive go code was responsible for several outages later down the road. It’s not the fault of the language of course, it’s just me not thinking about various failure scenarios, and performance degradation scenarios, and me not properly testing them.

Around the same time I was also setting up paid plans. At the launch there was only an unlimited free plan, but I needed to generate revenue, in order to at least pay for the servers. Otherwise, the project would not be sustainable long term.
First of all, I was and still am working as a contractor. Since I need to pay my taxes, I already had a registered company before diving into Healthchecks. This was fortunate because it was one less barrier for me to start the project. Taxes for the company are handled by outsourced accountants, which has been very helpful. I’m fine with paying taxes, but all the paperwork and burreaucracy I do not enjoy at all, so I try to avoid all of that as much as possible.
So, for payments, I looked at Stripe but it was not available in Latvia at the time.

I then looked at Braintree which seemed OK. Setting up an account with them was easy enough. There was a fair bit of development work on the Healthchecks side, to integrate with their API and to build out the functionality for entering a payment method, entering billing details, selecting a plan, generating invoices.
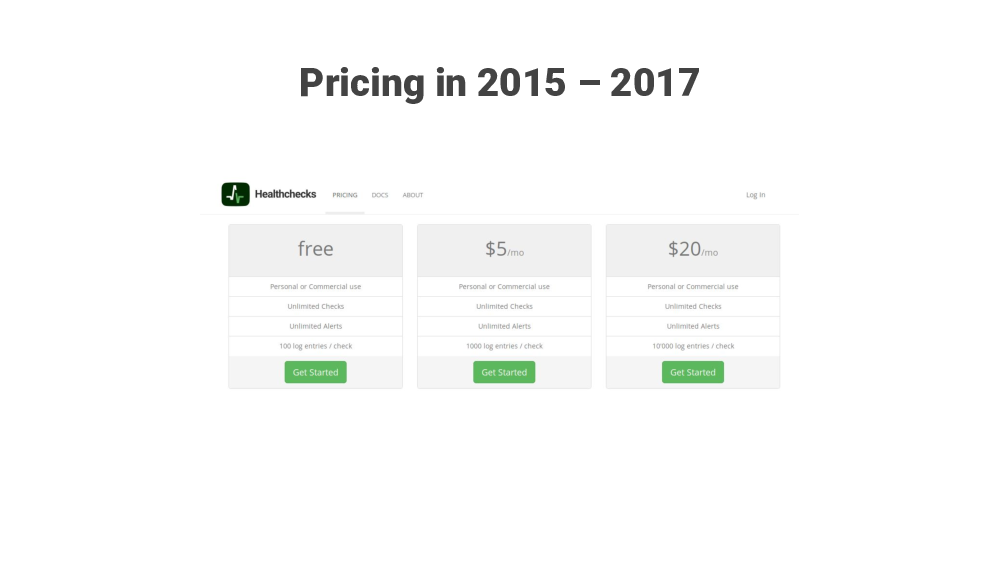
Initially, the price for the paid plan was $5/mo. The free plan was still practically unlimited, meaning there was little incentive to upgrade.
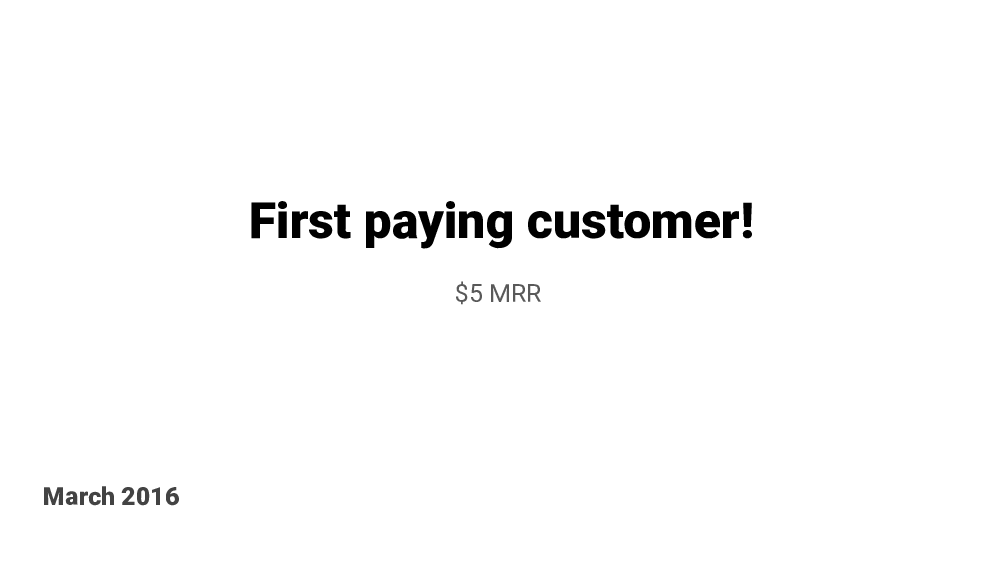
Nine months in Healthchecks got its first paying customer! $5 MRR.
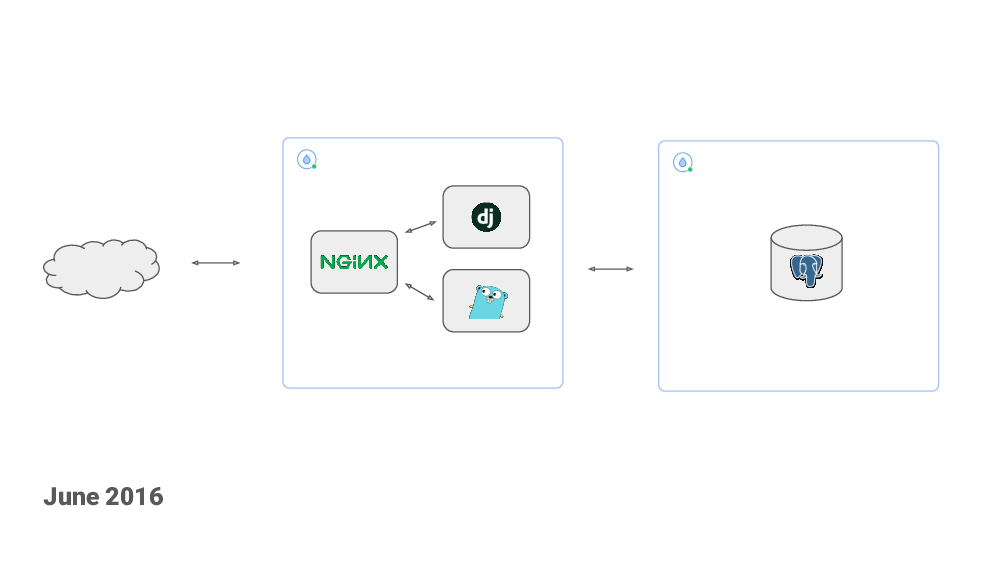
One year after starting the project, I moved from a single server setup to the web server and the database hosted on separate DigitalOcean droplets.
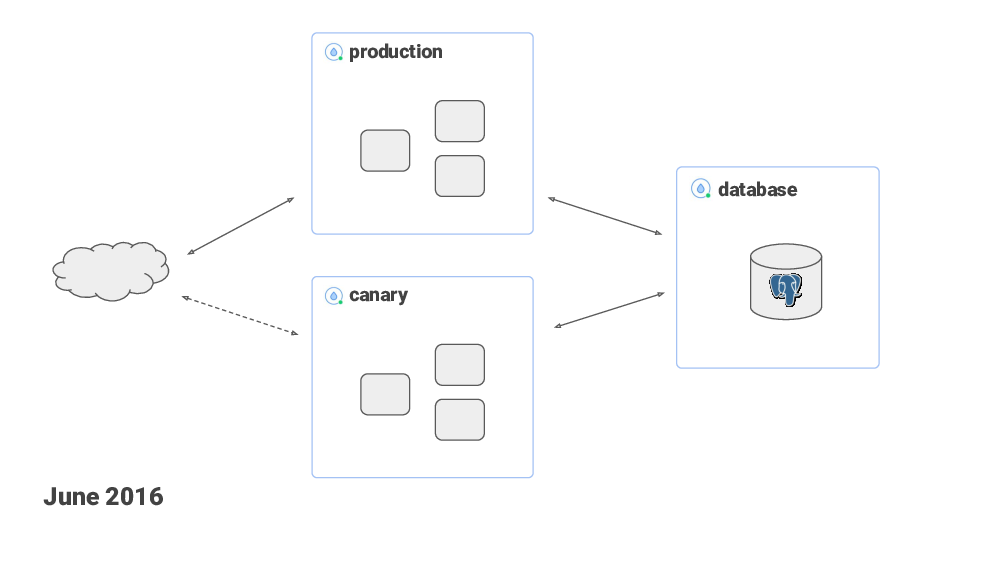
The web server used a floating IP. When I needed to deploy new code, I would create a new droplet, deploy the new code to it, do some smoke testing and if everything looked OK – switch the floating IP over to the new droplet. And I kept the old droplet around for a while so I could switch back in case of problems.

For deployment I used – and still use – Fabric with fabtools. I looked into Ansible as well, and used it for a while, but ultimately went back to Fabric because it’s less complex, less magic, is easier to reason about, and the deployments ran much faster.

I’m still using Fabric version 1.something, which uses Python 2.7. Not ideal. So I will need to deal with this in not too distant future, but it works fine for now.

August 2016, Healthchecks had an about 24 hour outage. I was away on a road trip to Estonia, I was not checking phone, and was completely unaware of the outage. When I returned home, my inbox was full emails, twitter was full of notifications and there was panic going on in github issues.

After this incident I did a few things, one was to get a dedicated second hand laptop with a working battery, and set up a development environment on it. It has a full disk encryption. It has a yubikey nano plugged in, for signing git commits and for SSH-ing into servers. It now comes with me wherever I go so I can fix issues when I’m away from home.
In 2017 I moved project’s hosting multiple times, as I was trying to improve the reliability, quality and fault tolerance of the service.
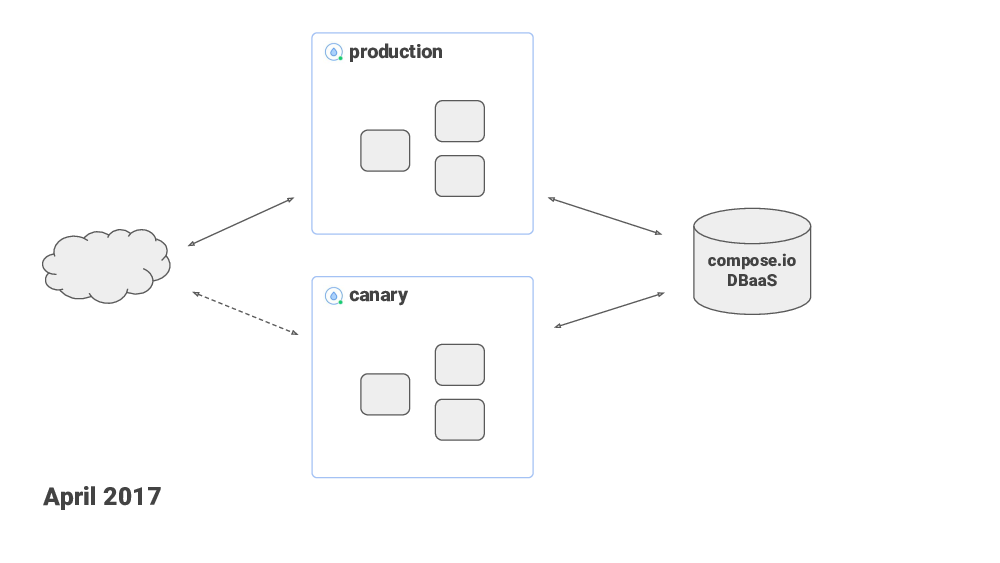
In April, I moved the Postgres database to compose.io, which is a DBaaS provider. The idea was that Compose.io would take care of managing database replication and automatic failover. It sounded good on paper and everything looked good in my preliminary testing, but, once I switched the production traffic to Compose, I was having capacity issues. In Compose you can scale up your database capacity – and your monthly bill – by simply moving sliders in their UI. I had to scale up to a point where it would be too expensive for me. So… Same month, I moved back to my previous setup.

By then, I had a clear idea of what I’m looking for in a hosting provider. One of the crucial things was a load balancer that could handle traffic spikes and do lots of TLS handshakes per second. If a load balancer can nominally do, say, 200 new HTTPS connections per second, but the site sees 1000 during traffic spikes then that’s no good. And the nature of cron jobs with common schedules is that traffic does come in waves.

Google’s Cloud Load Balancer looked like a good option – it is, you know – Google scale! In May 2017 I moved the service to Google Cloud Platform. They had also recently launched managed Cloud Database service, which was nice, and I made use of that as well.
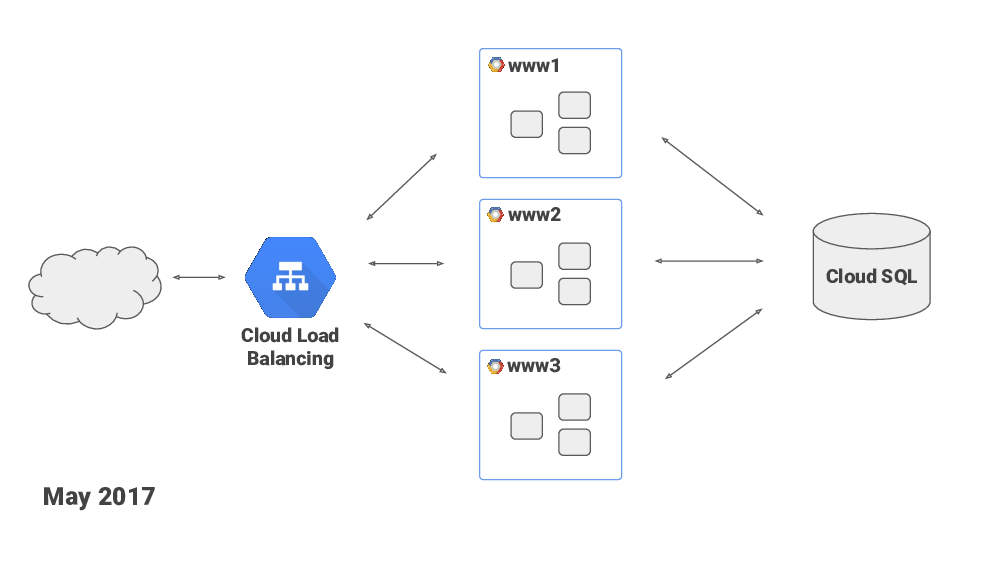
Google’s load balancer was handling any amount of TLS handshakes fine, but I was seeing occassional failed requests in the load balancer’s logs. And I spent good amount of time searching for solutions and troubleshooting – I was trying everything I could think of on my end, things like tweaking nginx parameters, I was also tweaking network-related kernel’s parameters. I opened issues with Google Cloud Platform’s customer support – they were very polite and willing to help, but didn’t seem to have the expertise or the access to engineers with the expertise.
They did suggest a few trivial things I had already tried. They found a relevant reddit post and sent me a link to it. Funny thing is, that post was written by me, I was documenting my issue and asking for advice there.
In short, I was unable to fix the issue with the failed requests, and I was looking for other options.
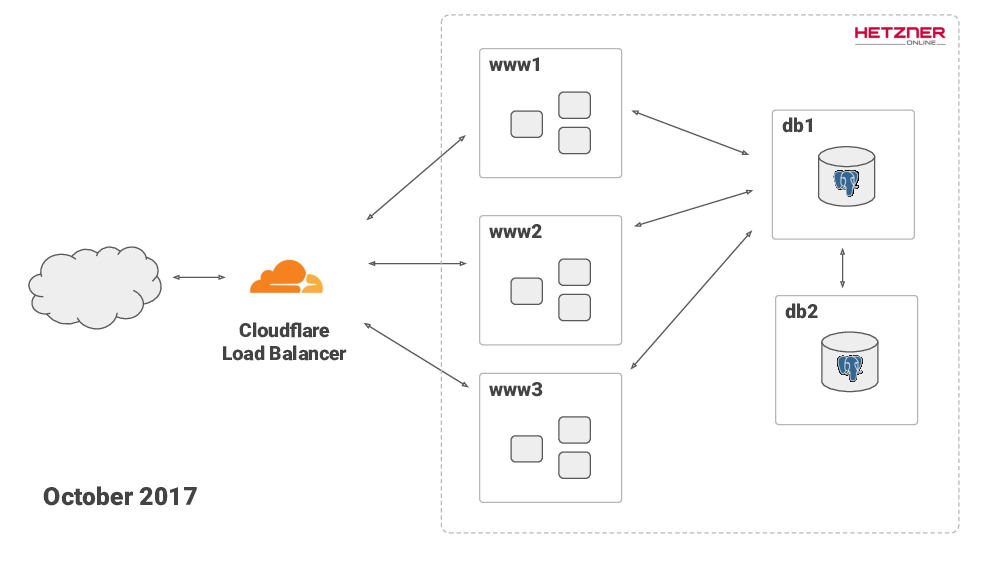
In October I moved to Hetzner for hosting, and to Cloudflare for load balancing. This is how the service is running today, I’m still using Hetzner and Cloudflare. By the way, Hetzner is a German hosting provider that has really good prices for bare metal servers.

OK, so I’ve been rehearsing this talk in the past week and this was the phrasing that was suggested by my brother: “I had an interesting problem – people wanted to pay me”.
So yeah, I needed to set up American Express payment processing in Braintree. The setup involved filling a few scary looking forms, printing and signing a contract with American Express, then scanning it and sending it back to them. In hindight, it wasn’t too hard. But the feeling at the time was, – “oh this is getting serious!”
In March 2018 I increased the paid plan’s price from $5 to $20 and tightened the free plan’s limits. I decided to do this after watching and reading a bunch of Patrick McKenzie’s talks, and his podcasts and blog posts that all had one main theme: “charge more!”.
I didn’t feel this was betraying the project’s original mission. After the change, Healthchecks still had the free plan with generous limits. The free plan would be aimed at individual users and maybe small teams with no budget. But for the paid plan, which was aimed at companies, $5 or $20 should not make a difference I thought.
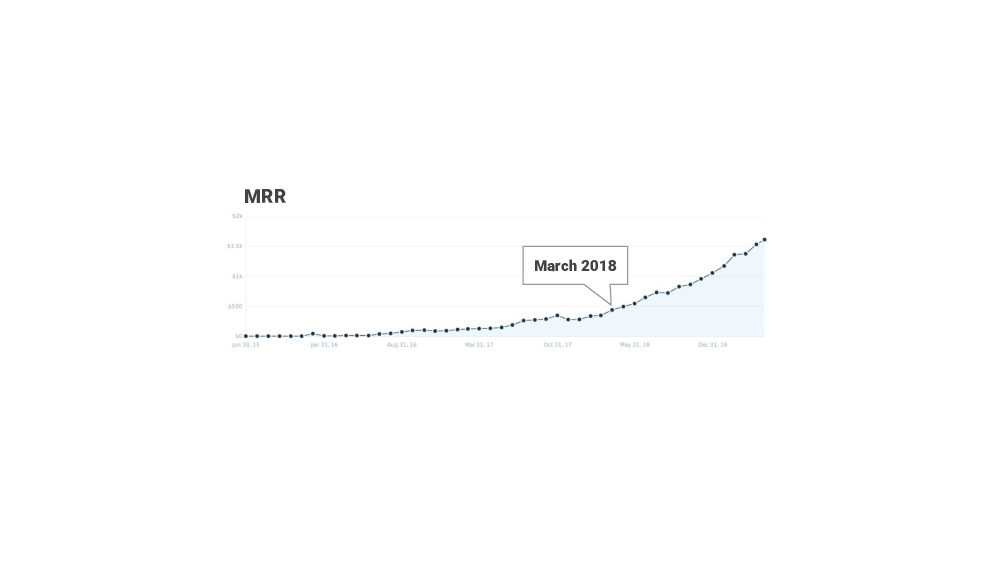
And, after the pricing change I didn’t get any negative feedback, which was nice, I was still seeing new signups, and the monthly recurring revenue graph started to look a bit more promising.

Last year around this time everyone was busy implementing the changes needed for GDPR compliance. And so was I. Luckily for me, the service was already in mostly good shape technically. It was not using any analytics services, so no cookie worries, it was not collecting unneeded personal data. Well, it does need to collect email addresses for sending notifications, and the users can specify mobile numbers for receiving text notifications, and, for the paid users, if they need proper invoices, then they have to enter their billing information of course. But that’s about it. I also needed to update the Privacy Notice document, like most everyone else.
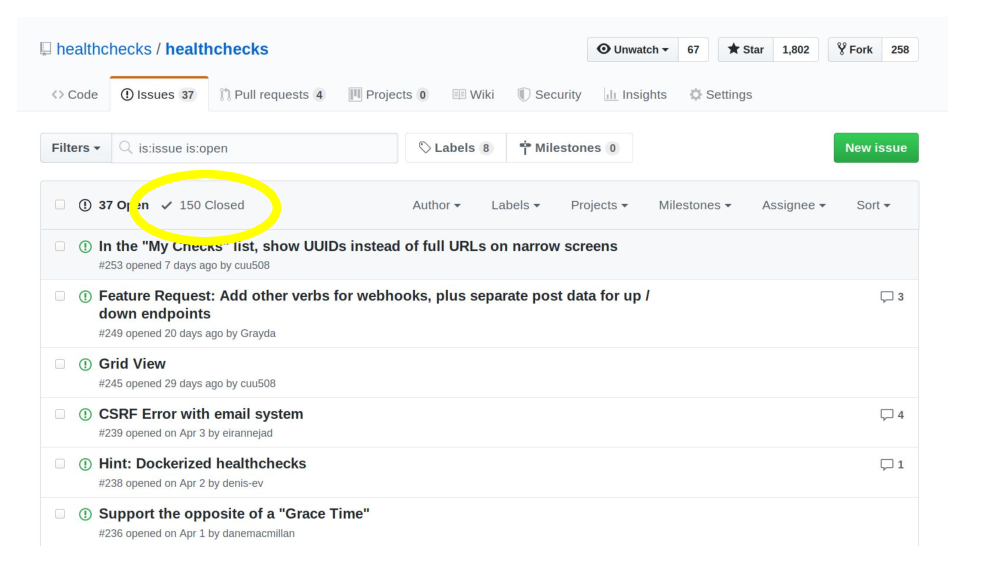
In parallel to these events – chasing down network reliability issues and changing hosting providers, I’ve of course also been working on adding new features and improving the existing features based on user feedback.

Now we are in May 2019, and here are some quick stats about the project. Healthchecks has over 6500 active user accounts, it is processing about 10M pings per day. That works out to a little over 100 pings per second. So – not too crazy but keep in mind the traffic is spikey.
Healthchecks.io currently has about 120 paying customers, and he monthly revenue is $1600. A chunk of that goes back into running costs, and in taxes, overheads and what not.
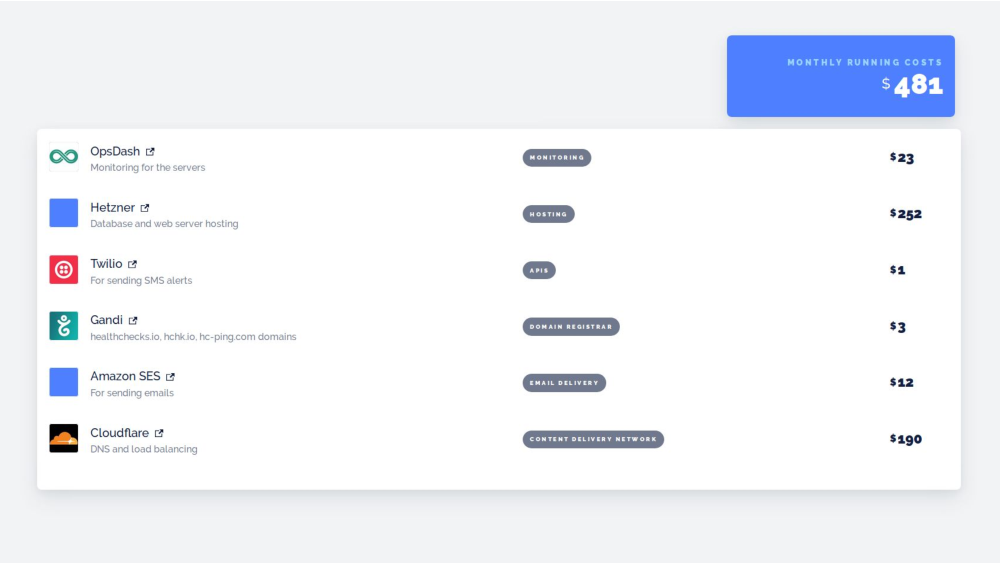
Healthchecks is still running on Hetzner’s bare metal servers. The Postgres database has a primary and a hot standby, and the failover is manual. I can trigger the failover with a single command, but, yes, that command is manual. I simply don’t trust myself to anticipate all the corner cases for doing this automatically. I’ve seen dedicated teams of people smarter than me mess this up, so I’m accepting that, for time being, the failover is manual.
At a high level, the app is still simple like it was in the beginning: a few load balanced web servers running the Django app and a Postgres database (and the ping handler written in go). There are no queues, no key value stores, no fancy distributed stuff – because as long as I can get away without using them, I want to keep things simple. That’s the theme here: simple and cheap.
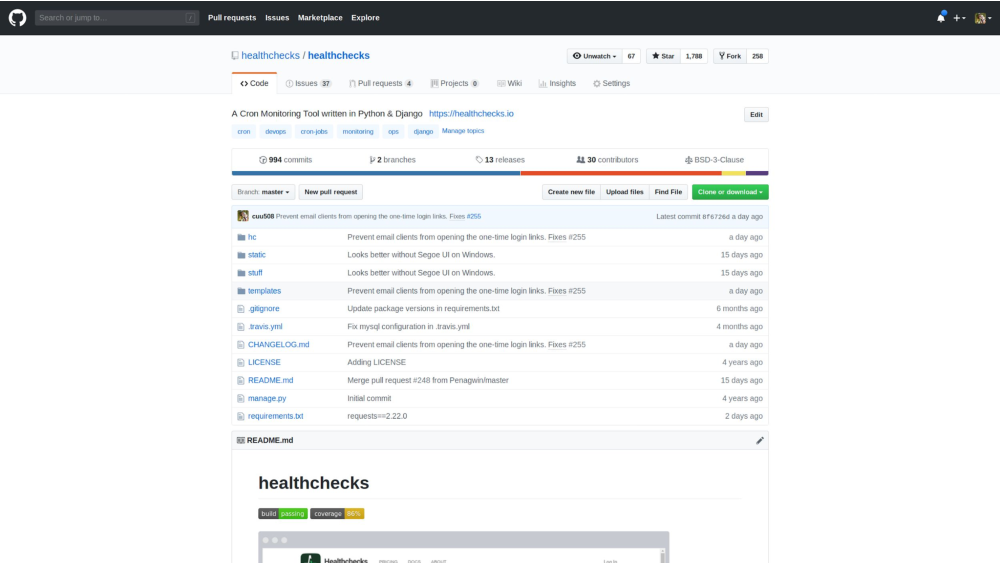
The Django app is still open source, and I know it is being self-hosted by more than a few people. I think open sourcing it was the right decision. I’m getting code contributions and bugfixes from time to time – mostly minor stuff but still very much appreciated.
So here’s something to think about: does the self-hosting option hurt my sales? I cannot say for sure but I estimate that, if yes, then – not by much. I think the self-hosting crowd falls into two groups: homelab enthusiasts who want to run stuff themselves for the fun of it, and companies who want to self-host because of custom needs or policy and compliance reasons. Neither group would be likely to be on a paid plan on the hosted version. So no big loss there.
Another question would be: if I look back at my “mission statement”, did I succeed? The service has lots of happy customers. Pretty much every support request starts with a “thank you for the great service”. I have also been sneakily using Slack App Directory to compare the popularity of Healthchecks and its competitors. And, at least according to this metric, Healthchecks is the most used one. So that’s good. But the big caveat is, Healthchecks is not yet paying for my time. I cannot yet afford to work on it full time. It is growing steadily though. An, luckily, I am in a fortunate position where I can afford to let it grow steadily and slowly.

Also, it has taught me a lot. It is a great addition to my CV.

My future plans are to keep making continuous improvements to the codebase based on user feedback. Continue the work on reliability and robustness improvements. Reach a point where it pays for my time and is not a hobby project any more, whenever that happens. After that, reach a point where it pays for a second person, so it does not rely on me alone.

Working on Healthchecks.io has has been great experience. I still enjoy working on it and I look forward to do more of it. This is my talk, thanks for listening!