In this article I will look at the current hosting setup of healthchecks.io, how it has evolved during the past two years, and what challenges I faced running this small but lively service.
DigitalOcean
When I first made the service public 2 years ago, it was running off a single $5/mo DigitalOcean droplet. It had a single CPU core and 512MB of RAM. The droplet was running both the Django web application and the Postgres database. Initially the service was receiving next to no traffic so everything was working well. A few months later I switched to a $20/mo droplet (two cores, 2GB RAM). I was deploying the code with a Fabric script, and had put some thought into avoiding downtime during code deploys.
Fast forward to June 2016. Feature-wise healthchecks.io was already useful, but its fault tolerance story was pretty bad. It was hosted on a single server with nightly database backups. As a first step, I decided to split up the components (database, healthchecks.io server, hchk.io server, background tasks) and run them on separate VMs. This helped some failure scenarios. For example, if the main website went down or experienced heavy traffic, hchk.io would still accept pings, and notifications would still be sent out. However, the database server going down would still be disastrous.
compose.io
The database being a single point of failure did not sit well with me, and I kept exploring options for a HA Postgres setup. It looked as if managing a fault-tolerant database cluster would be a full-time systems administration job in itself. I looked at the “pay someone else to do it” options. They were fairly limited by the tight budget I had. I could not afford Heroku Postgres with HA, for example, as it starts at $200/mo. After much consideration, I committed to go with compose.io. On paper their specs and pricing looked good, and I had tested their service with a snapshot of production data (but not with production-level traffic!) I even got to see their fail-over process in action. The database was unavailable for a few minutes during the fail-over, but it did come back up and continued to work without my intervention.
The move to compose.io did not go well. After I pointed production traffic to the new database, I soon started seeing a variety of Sentry reports about database connection problems. compose.io support advised me that my database was starved of memory, and recommended to scale its RAM allocation. Using their convenient scaling slider, I increased the RAM allocation and my monthly bill by an order of magnitude. After doing that, I was seeing fewer dropped database connections but they were still fairly regular. At this point I was:
- getting complaints from users
- waking up every 3 or so hours during the nights to check up on services
- paying significantly more than originally planned
- not getting actionable advice from compose.io support on how to troubleshoot my connection issues
Linode
Given enough time with tcpdump and WireShark I would probably have solved my dropped connection issues. But I needed to fix things fast. I gave up the HA requirement and moved the database back to a plain VPS. This time I went with Linode for two reasons:
- it had slightly better pricing than DigitalOcean.
- I was going to use TLS-terminating load balancers. DigitalOcean had just launched theirs. Linode’s NodeBalancers had been around for a while and seemed a safer choice. Also, they supported IPv6, DO did not.
I updated my deployment scripts, made a migration plan, did a few dry runs, slept on it, and then migrated over to Linode. Error reports ceased, and my monthly bill was in check again. But once again the database was a single point of failure. On the bright side, I was now load balancing the incoming HTTP requests, and my service could tolerate the loss of a web server node.
The traffic that hchk.io receives comes in bursts. On average, it receives around 30 requests per second, but there is a short traffic spike (hundreds of requests at once) every five minutes, a bigger spike every round hour, and a period of elevated request rate every midnight (UTC).
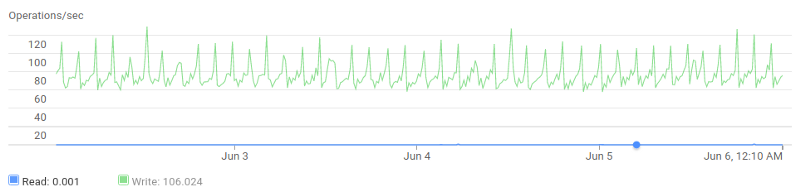
hchk.io traffic also is unusual in that every request is a “one-off” and needs to do a brand new TLS handshake. I learned that a single NodeBalancer can only do about 200 TLS handshakes per second. During the traffic spikes the load balancer was becoming a bottleneck. Requests would sometimes take 3+ seconds to complete. Clients that use aggressive timeout settings would see them as failed requests. A band-aid fix was to add a second load balancer, and split the traffic between the two using round-robin DNS.
I also learned that DigitalOcean’s load balancers have similar TLS handshake performance to Linode’s so they were no good either. Looking further, I found that Google’s Cloud Load Balancer can handle as many handshakes as I could throw at it. And it had IPv6 support, albeit in alpha preview state, too! So I started plotting a move to Google Cloud Platform.
Google Cloud Platform
I went through the migration process once again, and, starting from May 4 2017 healthchecks.io has been running on Google Cloud Platform. The current setup is:
- a managed Cloud SQL database. Postgres on Cloud SQL is currently in beta and they don’t have the HA option yet, but hopefully that is coming in the future
- three app servers, provisioned by my plain Fabric scripts
- Google’s Cloud Load Balancer splits traffic between the three app servers
I experimented with GKE, Google’s managed version of Kubernetes, but ultimately opted to keep things simple and straightforward: plain virtual machines and plain Fabric commands for various administrative tasks.
Once I started exploring Google Cloud Platform’s logging tools I came across concerning “502 Bad Gateway” log messages coming from the load balancer. They were infrequent and so took a long time to troubleshoot (make a configuration change — monitor logs for a few days to see if errors are gone — repeat), but I am cautiously optimistic these are now fixed for good. In short, I had to tune a number of sysctl parameters and nginx options so my app servers could properly handle bursts of new connections. The following resources helped a lot:
- Compute Engine: Tips, Troubleshooting & Known Issues
- Tuning NGINX behind Google Cloud Platform HTTP(S) Load Balancer
- Optimizing servers — Tuning the GNU/Linux Kernel
- Tuning NGINX for Performance
For updating code on app servers I am using the “rolling update” pattern: take an app server out of load balancer rotation, update it, put it back in rotation, then move on to the next app server. Here is an outline of this process for a single server:
def update():
# Going down...
maintenance_on()
stop_sendalerts()
stop_sendreports()
print("sleeping for 120s")
# Wait for load balancer to fail us
time.sleep(120)
# Actual update
www()
hchk()
nginx()
# Coming up...
print("sleeping for 30s")
time.sleep(30)
maintenance_off()
start_sendalerts()
start_sendreports()
print("sleeping for 120s")
# Wait for load balancer to declare us healthy
time.sleep(120) maintenance_on() puts the server in “maintenance mode”. When in maintenance mode, the server can still process incoming requests, but it starts reporting itself as unhealthy to the load balancer, and load balancer gradually diverts traffic away from it. It takes a while for the load balancer to update, so the script waits 120 seconds before it goes ahead with updating and restarting. A complete update takes some time, but it is completely transparent for the end users … as long as I am not deploying backwards-incompatible database schema changes!
This is where healthchecks.io is now, hosting-wise. Page load times are good. No 5xx errors in the load balancer logs (fingers crossed!). The database is currently not fault tolerant but hopefully that will change in the future. Monthly bill from Google is in the $150-$200 range.
Lessons learned
When evaluating a product or service, it is imperative to test it with production-level workload. I learned this with my compose.io fiasco, and also when I hit NodeBalancer’s capacity limits.
Simple problems I can often solve myself. When I needed help with harder problems, and tried contacting Support, I was getting what I paid for, so to speak:
- Responses from compose.io support were about as useful as Richmond’s comments on flashing lights.
- Google charges for support separately. It starts at $150/mo for the Silver plan.
- Linode gave me a straight and honest answer about NodeBalancer limitations, which I appreciated.
Finally, as I was looking for solutions, I explored a number of tools and technologies which I did not ultimately end up using. They all go into the “bag of tricks” and may be useful in future projects.

With that, thanks for reading! And, if you are not yet monitoring your cron jobs and background tasks for silent failures, I welcome you to check out healthchecks.io!
— Pēteris Caune, healthchecks.io